一、數(shù)據(jù)日志存儲:Kafka的核心基石
Apache Kafka 作為一個高吞吐量的分布式消息系統(tǒng),其核心設(shè)計之一便是高效、持久且可靠的數(shù)據(jù)日志存儲。Kafka 的所有消息(記錄)都以追加(Append-only)的方式順序?qū)懭氲酱疟P的日志文件中,這種設(shè)計帶來了優(yōu)異的讀寫性能。
存儲結(jié)構(gòu):
- 主題(Topic)與分區(qū)(Partition): 每個主題被劃分為一個或多個分區(qū),每個分區(qū)在物理上對應(yīng)一個目錄。
- 日志段(Log Segment): 每個分區(qū)又被進(jìn)一步劃分為多個日志段文件。活動段(active segment)負(fù)責(zé)接收新數(shù)據(jù)的寫入,舊段文件在滿足一定條件(如時間或大小)后變?yōu)椴豢勺儯⒖赡鼙磺謇砘驂嚎s。
- 索引文件: 為加速消息查找,Kafka 為每個日志段維護(hù)了位移索引(.index)和時間戳索引(.timeindex)文件,通過稀疏索引實現(xiàn)快速定位。
二、消息格式的演變與優(yōu)化
Kafka 的消息格式(Record Format)歷經(jīng)了多次重要迭代,旨在提升效率、降低開銷并支持更豐富的功能。
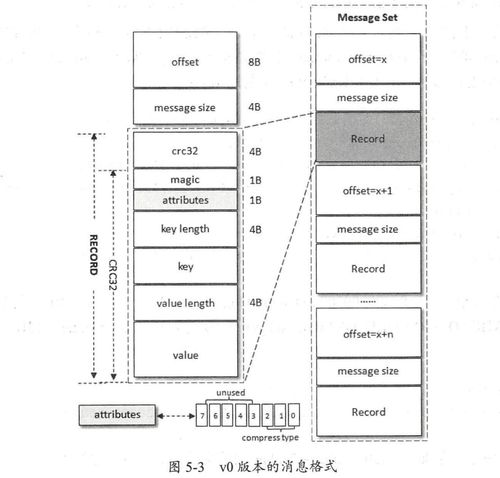
- V0/V1 格式(經(jīng)典格式):
- 早期版本,消息批處理能力較弱,每條消息都包含完整的元數(shù)據(jù)(如CRC、魔術(shù)字、屬性、時間戳等),網(wǎng)絡(luò)和存儲開銷相對較大。
- V2 格式(自Kafka 0.11.0引入):
- 引入消息批次(Record Batch): 將多條消息聚合為一個批次進(jìn)行存儲和傳輸,批次頭包含該批次公共的元數(shù)據(jù)(如首次位移、時間戳等),極大地減少了每條消息的元數(shù)據(jù)冗余。
- 更緊湊的變長字段: 使用變長整數(shù)(Varints)編碼,進(jìn)一步減少了空間占用。
- 支持冪等性和事務(wù): 消息批次格式為 Kafka 實現(xiàn)精確一次語義(EOS)提供了基礎(chǔ)。
格式的演進(jìn)顯著降低了網(wǎng)絡(luò)傳輸和磁盤存儲的開銷,是 Kafka 實現(xiàn)高吞吐的關(guān)鍵之一。
三、日志壓縮:保留關(guān)鍵狀態(tài)
Kafka 提供了兩種日志清理策略:基于時間的刪除和基于日志壓縮(Log Compaction)。
日志壓縮是一種特殊的存儲優(yōu)化機(jī)制,它確保對于同一個 Key 的消息,Kafka 分區(qū)最終只保留其最新的 Value(即最后一條消息)。
- 工作原理: 后臺的壓縮線程會定期掃描日志,對于具有相同 Key 的消息,只保留位移最大的那條(最新值),刪除舊的版本。沒有 Key 的消息不會被壓縮,通常會被基于時間的策略清理。
- 應(yīng)用場景: 主要用于存儲數(shù)據(jù)庫變更日志(CDC)、應(yīng)用狀態(tài)快照等場景。例如,可以存儲一個用戶的最新配置、一個商品的最新價格。消費(fèi)者可以從頭讀取壓縮后的日志,獲得所有 Key 的完整最新狀態(tài)。
- 保證: 壓縮操作不會改變消息的順序,也不會影響消息的位移(Offset)。它提供的是“最終”的鍵值存儲視圖。
四、數(shù)據(jù)處理與存儲服務(wù):從管道到平臺
憑借其強(qiáng)大的存儲能力,Kafka 早已超越了簡單的消息隊列角色,演變?yōu)橐粋€實時的流式數(shù)據(jù)處理與存儲平臺。
- 作為流式數(shù)據(jù)管道:
- Kafka 是連接不同數(shù)據(jù)系統(tǒng)(如數(shù)據(jù)庫、應(yīng)用、Hadoop、數(shù)據(jù)倉庫)的可靠中樞,實現(xiàn)數(shù)據(jù)的實時流動。生產(chǎn)者和消費(fèi)者模型解耦了數(shù)據(jù)生產(chǎn)方和消費(fèi)方。
- 作為存儲層:
- Kafka 持久化、可復(fù)制的日志設(shè)計使其本身成為一個高效的存儲系統(tǒng)。數(shù)據(jù)可以按需保留很長時間(數(shù)天甚至數(shù)年),供多個消費(fèi)者以各自的速度和時機(jī)進(jìn)行讀取(包括回溯歷史數(shù)據(jù)),這是傳統(tǒng)消息隊列難以做到的。
- 與流處理集成:
- Kafka Streams: 一個用于構(gòu)建實時流處理應(yīng)用的客戶端庫,直接利用 Kafka 作為狀態(tài)存儲(State Store)。其底層正是利用了 Kafka 分區(qū)的日志存儲和壓縮機(jī)制來持久化應(yīng)用的本地狀態(tài),實現(xiàn)了容錯和可擴(kuò)展的流處理。
- ksqlDB: 建立在 Kafka Streams 之上的流式 SQL 引擎,允許用戶使用 SQL 語句對 Kafka 中的數(shù)據(jù)進(jìn)行查詢、轉(zhuǎn)換和持久化,進(jìn)一步簡化了流處理應(yīng)用的開發(fā)。
- 連接器生態(tài)(Kafka Connect):
- 提供了大量預(yù)構(gòu)建的連接器,可以輕松地將外部系統(tǒng)的數(shù)據(jù)導(dǎo)入 Kafka(Source Connector)或?qū)?Kafka 的數(shù)據(jù)導(dǎo)出到其他存儲系統(tǒng)(Sink Connector)。這使得 Kafka 成為整個數(shù)據(jù)生態(tài)的樞紐,統(tǒng)一了數(shù)據(jù)存儲和分發(fā)的接口。
##
Kafka 的數(shù)據(jù)日志存儲是其所有高級特性的根基。從高效的日志段和索引設(shè)計,到不斷優(yōu)化的消息格式,再到提供關(guān)鍵狀態(tài)保留能力的日志壓縮,這些存儲層的創(chuàng)新共同支撐了 Kafka 的高性能與可靠性。在此基礎(chǔ)上,Kafka 通過 Streams API、Connect API 等,將自身從一個高性能的消息總線,升級為一個完整的實時流式數(shù)據(jù)處理與存儲服務(wù)平臺,使得數(shù)據(jù)的存儲、流動和處理能夠在同一個系統(tǒng)中無縫銜接,滿足了現(xiàn)代數(shù)據(jù)密集型應(yīng)用的苛刻需求。